Sequence Labeling
Linguistic sequence labeling is a general modeling approach that encompasses a variety of problems, such as part-of-speech tagging and named entity recognition.
Challenges
Recent advances in neural networks (NNs) make it possible to build reliable models without handcrafted features. However, in many cases, it is hard to obtain sufficient annotations to train these models.
Our Solution
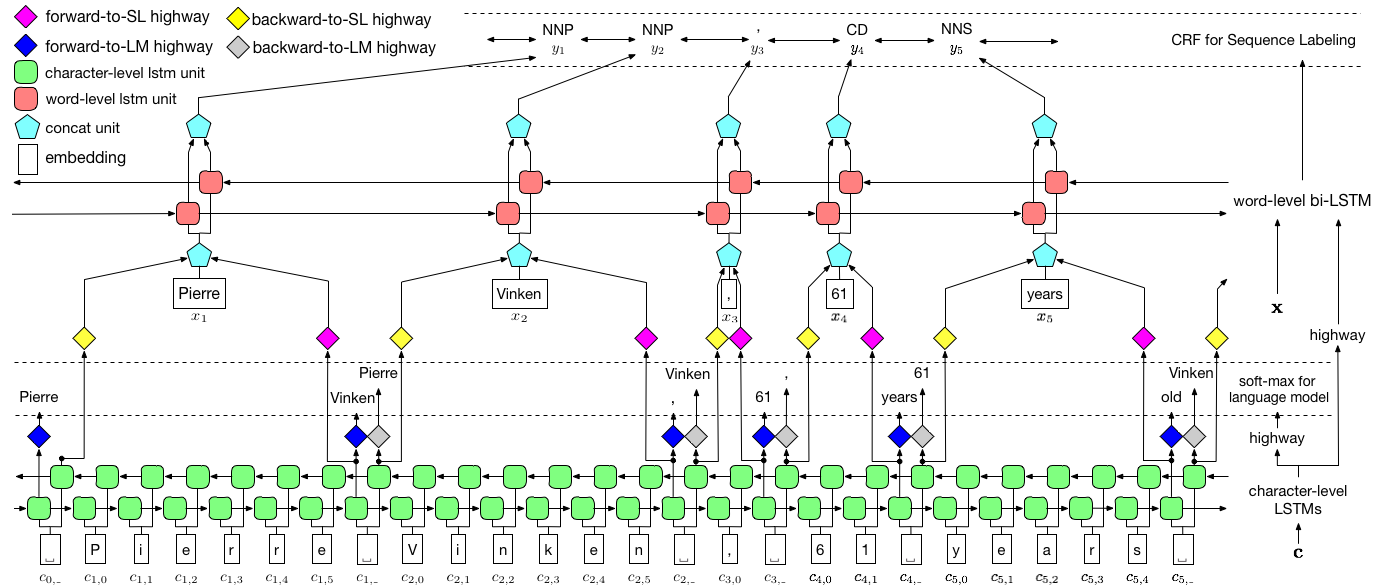
As visualized above, we use conditional random field (CRF) to capture label dependencies, and adopt a hierarchical LSTM to leverage both char-level and word-level inputs. The char-level structure is further guided by a language model, while pre-trained word embeddings are leveraged in word-level. The language model and the sequence labeling model are trained at the same time, and both make predictions at word-level. Highway networks are used to transform the output of char-level LSTM into different semantic spaces, and thus mediating these two tasks and allowing language model to empower sequence labeling.
Experiments
Here we compare LM-LSTM-CRF with recent state-of-the-art models on the CoNLL 2003 NER dataset, and the WSJ portion of the PTB POS Tagging dataset. All experiments are conducted on a GTX 1080 GPU.
NER
When models are only trained on the CoNLL 2003 English NER dataset, the results are summarized as below.| Method | Max(F1) | Mean(F1) | Std(F1) | Time(h) |
|---|---|---|---|---|
| LM-LSTM-CRF (our) | 91.35 | 91.24 | 0.12 | 4 |
| -- HighWay | 90.87 | 90.79 | 0.07 | 4 |
| -- Co-Train | 91.23 | 90.95 | 0.34 | 2 |
POS
When models are only trained on the WSJ portion of the PTB POS Tagging dataset, the results are summarized as below.| Method | Max(F1) | Mean(F1) | Std(F1) | Reported(F1) | Time(h) |
|---|---|---|---|---|---|
| Lample et al. 2016 | 97.51 | 97.35 | 0.09 | 37 | |
| Ma et al. 2016 | 97.46 | 97.42 | 0.04 | 97.55 | 21 |
| LM-LSTM-CRF (our) | 97.59 | 97.53 | 0.03 | 16 |
Bib Tex
Please cite the following paper if you find the codes and datasets useful.
@inproceedings{2017arXiv170904109L,
title = "{Empower Sequence Labeling with Task-Aware Neural Language Model}",
author = {{Liu}, L. and {Shang}, J. and {Xu}, F. and {Ren}, X. and {Gui}, H. and {Peng}, J. and {Han}, J.},
booktitle = {AAAI},
year = 2018,
}